Budibase Core. A Serverless Database Engine, for fast SaaS development.
At Budibase, we are building a platform for accelerated development and easy management of SaaS businesses. We are beginning at the very bottom of the stack, by inventing a database engine specifically for this purpose. This post will attempt to give a good overview of what we are trying to achieve. I will get into detail in later posts.
What we need from a database
A key requirement of Budibase is the ability to reduce repetition. We should be able to declare our data structures and rules in one place, and apply everywhere - frontend and backend.
Initially, Budibase will target SaaS applications for small to medium sized teams. So, we expect to be able to handle ~20 record creates/updates per second, into a single dataset or “Instance”. Depending on the application, this could equate to ~100 or more concurrent users, on a single instance.
Instances should be horizontally scalable. Creating and managing many thousands of instances (I.e. customers) should be trivial.
A collection of records should be able to hold multiple millions of records.
A dataset should be single tenant. I.e. Customers’ data should be segregated from other customers.
Management of the database should be easy. This includes schema & rules updates, backups, dataset creation and copying.
The end storage engine should be interchangeable, allowing us to drive up performance of a single instance, if necessary.
Database engine threads should operate without shared memory. This will enable us to horizontally scale a stateless web server component, or even use “Serverless Cloud Functions”, e.g. Azure Functions or AWS Lambda. This will enable a new paradigm for databases - multiple clients writing structured data directly to disk, without a server in between.
In Terms of Actual Features…
- Define record “types”, with a defined schema (i.e. set of fields). Fields will have types.
- Define validation rules for records, written in javascript.
- Define collections of records.
- Declare “indexes” - by which we mean a “view” on a collection. This would be declared in the form of a “map” and “filter” function, written in javascript. Indexes will be the only way to list records.
- Declare aggregate (summary) functions on an index.
- Declare relationships between record types (with referential integrity).
- Records may have child collections.
- Define user roles, that define which records/collections/indexes may be viewed and edited by users who have this role applied.
- Create, read, update and delete operations on records.
- Validate a record (according to previously defined rules).
- List items in an index.
- Search an index.
- Handling of database updates when the definition is changed.
Budibase Core - The Serverless Database (actually - no db server) .
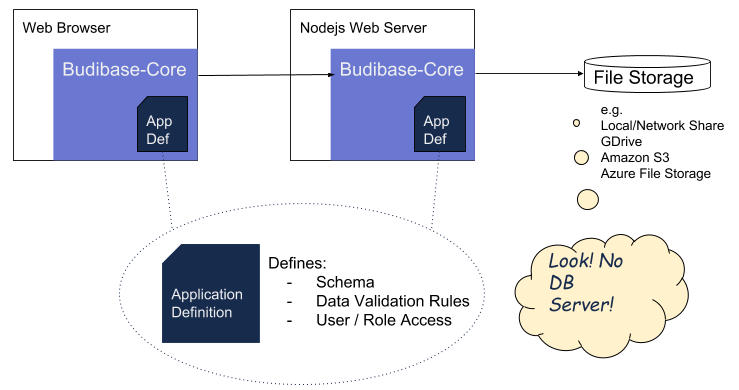
Above, is a simplified version of one mode of working with Budibase core. Key Points are
- The “Budibase Application Definition” will define various rules and structures of our data. This will be shared and understood on both the client and server. This will allow us to always keep the user interface consistent with what’s allowed on the backend. We will explore this in more depth in a later post.
- The Budibase Core library, on the server, will store all data as standard files on a file storage service.
- The actual file storage service used by Budibase will be pluggable (e.g. for a super fast instance, we could plug it into Redis).
Not clear from the above picture:
- There will be no shared memory, between server threads. All shared state will be stored as files in our file store.
- A single dataset (represents one team) will be stored under one root folder.
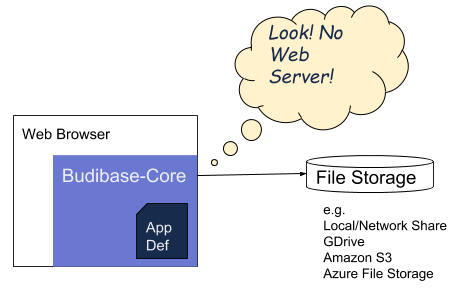
Additionally, these features (or constrains?) open up a new paradigm for structured data storage. We now have the option of connecting an app directly to file storage - no web server required. Of course, in doing so, we will lose some features that an always-on, trusted web server can provide us. That discussion is for another post.
Trade-Offs
We will not achieve these features without giving something up, over a traditional database.
- Performance. Budibase is not for Big Data. It is not for high throughput or very low latency requirements. Budibase is made for building web applications for small to medium sized teams - while still provisioning for a large number of separate teams.
- Data segregation. Whilst good for security and performance, physically segregating instances in this way reduces our ability to query data across all instances. Tools can be built to do this, it’s just more difficult.
- Eventual Consistency. When an update is made, it will succeed or fail. If it succeeds, it may not immediately appear in lists, aggregates and searches. The record will always be immediately available, if accessed directly.
- No Partitions. Budibase will not support partitioning of data, in a single instance. We do not see this as necessary for the size of the datasets that we are aiming for. Separate instances can be physically partitioned with ease.
Summary
Budibase Core is a Javascript library that turns any file-storage-like service into a structured datastore. It will initially target applications that are meant for teams of < 100 users (although this number can be improved). Using a Javascript library to be the sole manager of data on disk, will enable Budibase to understand and apply one set of application rules across the entire application stack. This is the base from which we will build Budibase, a platform-as-a-service for developing and managing SaaS applications.
P.S. We are open source.